Lessons from Early Stage SaaS
I recently came across a hot take from Gokul Rajaram on a podcast about the current wave of AI startups. The TL;DR version: he warns against building SaaS companies that use AI to replicate the jobs already being done by horizontal SaaS companies. His argument is that it’s relatively easy for SaaS incumbents to develop function-specific AI (e.g., QuickBooks for accounting). Instead, he is bullish on the verticalization of software (e.g., CRM software tailored for lawyers). This insight isn’t entirely surprising when you consider how markets are likely to evolve in the medium-term to long-term. AI has actually strengthened the position of incumbents, who already have customer data and established relationships. For a startup to truly differentiate itself, it has to go deep into a niche market, where it’s less likely to attract direct competition from these larger players.
However, listening to Gokul’s take made me reflect on my time at Finicast. In this post, I try to gather some learnings from that experience and share some observations that might help early-stage founders looking for problems at the intersection of SaaS and AI.
Finicast Experience
Finicast was an Enterprise SaaS startup building collaborative planning software for FP&A teams. The company developed a novel database system to overcome the limitations of in-memory databases, which were the preferred choice of most other enterprise planning products. While we initially focused on financial planning, the broader vision was to enable seamless “connected planning,” eliminating the need for spreadsheets across enterprises. The technology had the potential to be transformative— much like Airtable— but unfortunately, the startup didn’t make it to the Series-A stage.
Finicast’s value proposition was its fast time-to-value and easy-to-maintain planning workflows. Planning software as a category is notorious for its long implementation cycles (more) given the degree of customizations required. For larger enterprises, these cycles usually take 4-6 months before they begin seeing any real value. Mid-market enterprises, in contrast, typically have shorter implementation cycles (1-3 months). They often rely on software that is somewhat templatized but flexible enough to meet their specific needs effectively. Another contributing factor to the long time-to-value is the behavioral change that planning software vendors often demand from their users— FP&A professionals. These users typically come from business, finance, or accounting backgrounds, but using planning software requires them to learn about dimensions and think more like engineers or database experts. As a result, there is a steep learning curve.
At Finicast, we were aiming for a time-to-value of weeks, and not months. We noticed our customers (and customer success team) had to spend a lot of time cleaning, processing and validating data. To reduce this, I led the development of a feature called “multi-dimensional data imports.” The goal was to make it easy for our users to import spreadsheet schedules and extract dimensions that could then be used to build models. This approach aimed to deliver an “aha!” moment quickly, offering immediate value to users rather than making them wait 2-6 months to see the benefits. It also helped onboard FP&A teams more smoothly by familiarizing them with the concept of dimensions early in the process.

The Schleps
While Finicast wasn’t an AI-first company, clean data was crucial. It was evident just how complicated the process of importing clean data could be. In larger enterprises with ERP systems, data cleaning and validation are typically part of the workflow, yet this process is anything but straightforward and requires a team of data engineers to maintain robust data pipelines. The challenge grows when integrating multiple systems, such as Salesforce, HubSpot, or NetSuite, making it increasingly difficult to establish a “single source of truth.” Without clean data, effective planning becomes nearly impossible (related problem, but in marketing context).
At the time, I wondered if I had encountered an instance of what Paul Graham refers to as Schlep Blindness — the tendency to overlook tedious tasks that hide startup opportunities in plain sight. Schlep, meaning an unpleasant and laborious task, is something everyone avoids, but as Graham notes: “Some ideas so obviously entail alarming schleps that anyone can see them. How do you see ideas like that? The trick I recommend is to take yourself out of the picture. Instead of asking ‘what problem should I solve?’ ask ‘what problem do I wish someone else would solve for me?’” At the time, I wished someone solved that data cleaning and validation problem for me! While several companies were tackling data-quality-related problems, this space clearly could have benefited from more products.
For AI-first companies, clean data isn’t just important— it’s a prerequisite. Core business logic, often driven by deep learning models, hinges on the quality, quantity, and preparation of data. Processes like prompt engineering and fine-tuning directly impact model performance. Seamless data pipelines are non-negotiable, yet data frequently becomes the Achilles’ heel of AI-first businesses, as each faces its own unique challenges.
Addressing these issues is both time-consuming and complex, which is why many horizontal startups tend to avoid them. Instead, they focus on delivering high-value decision-making solutions. After all, companies get paid for outcomes, not for the grunt work of cleaning data. This dynamic may shift with the rise of AI, but for now, horizontal incumbents will likely integrate AI wherever clean data is easily available and then cross-sell/up-sell their offerings. This leaves limited room for new startups, except to create vertical software and embed themselves deeply into workflows for their targeted niches.
Learnings from Building Vertical Software for Enterpirses
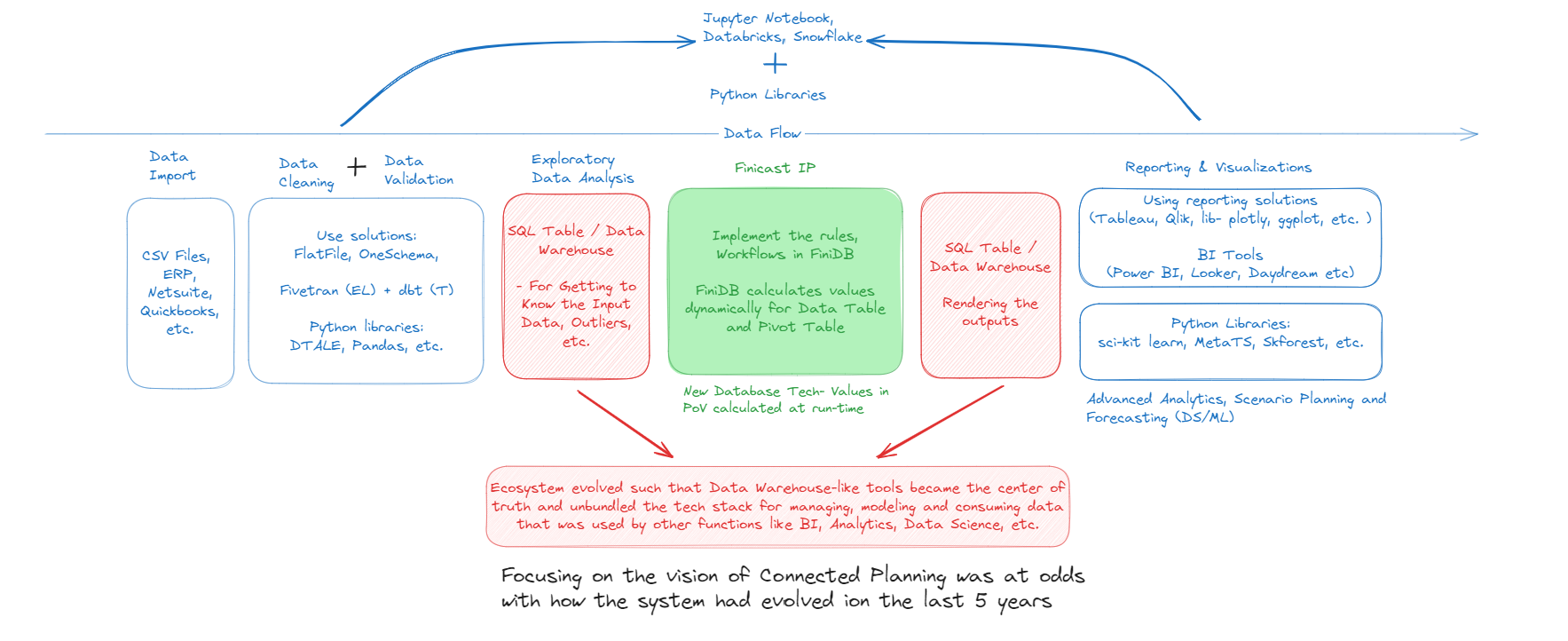
Building vertical software, however, presents its own set of challenges, particularly when serving enterprises. Before developing the “multi-dimensional data import” solution in-house, we explored different tools to clean and validate data. We experimented with tools to create data pipelines such as Jupyter Notebooks with Pandas/D-Tale, Snowflake, Dataiku, Databricks, Airflow, etc. The idea was to focus on what we did best— software for building models— and make use of a data warehouse-like solution for leveraging best-in-class tooling for data cleaning, reporting, analytics, etc. However, this approach didn’t align with our original vision of creating a vertical software for “connected planning.” To be fair, the vision of connected planning had strong appeal because it promised a significant venture outcome, similar to Anaplan. But it required a large upfront investment so that the product was “enterprise-ready.”
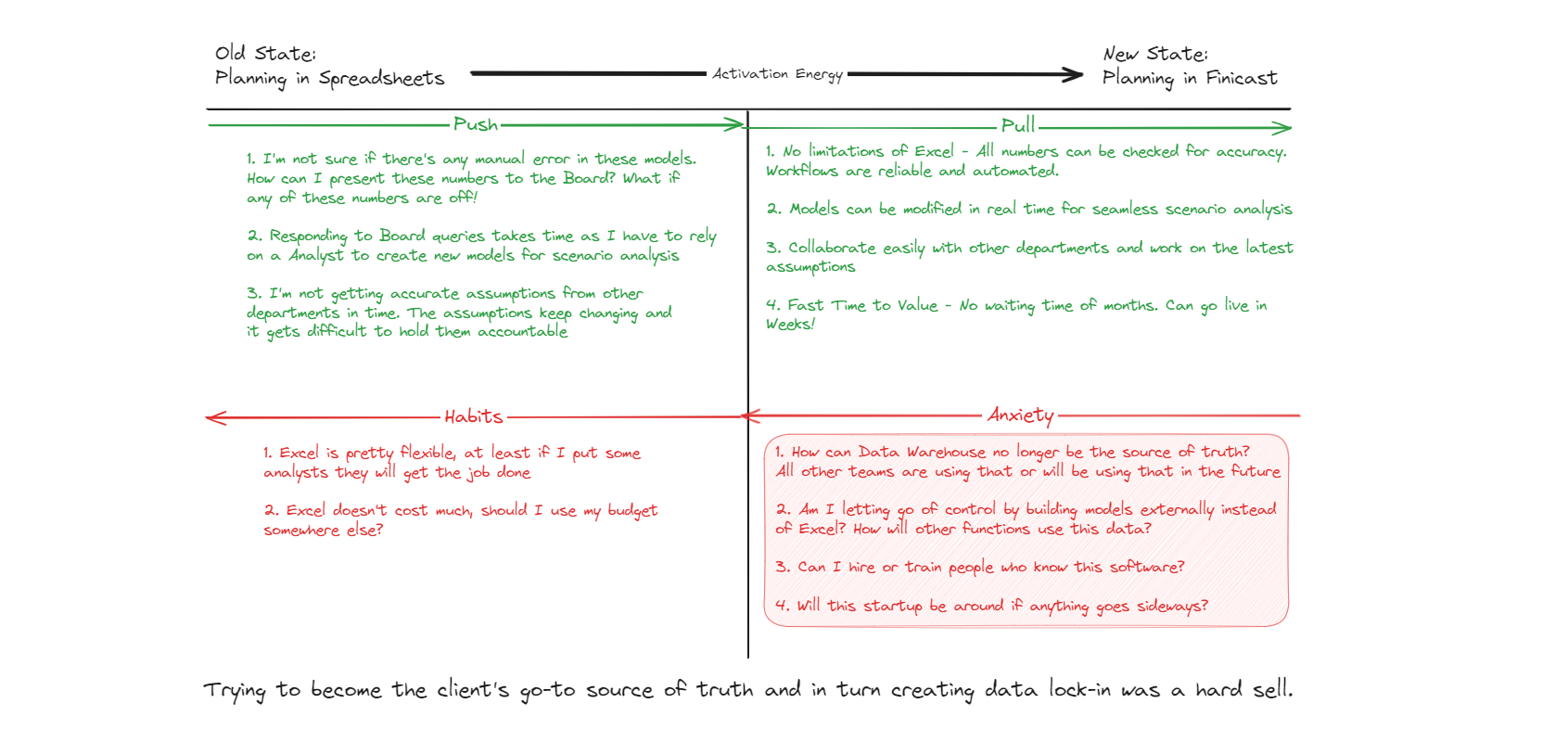
It’s difficult to generalize such statements but I think building vertical software for enterprises is tricky primarily due to long sales cycles. While short feedback cycles can help mitigate some risk, ultimately, actual customer purchases provide the most valuable feedback. If the product fails to attract customers soon after launch, one starts questioning if the team is heading in the right direction. While personal experience with the pain point gives greater conviction, one is still looking for data to validate their efforts. The longer it takes to recover the money invested, the greater the risk of building the wrong product early on. Once some software has been shipped it introduces a host of biases within the team that can then be hard to overcome. Keeping team lean is usually the best way to manage this early stage uncertainty- it buys both time to course correct and improves coordination within the team.
A key signal that you’re on the right track is when customers show eagerness to adopt the product, often reflected in shorter sales cycles. However, the need for more human touchpoints to close deals and ensure customer success increases customer acquisition costs (CAC), putting pressure on both pricing and margins. Higher-priced software typically extends sales cycles, which, in turn, limits your growth channels. Longer sales cycles also mean longer feedback loops, which slow down the team’s ability to iterate quickly and adjust the product in the right direction. If not carefully managed, the cumulative effect of longer sales cycles can quickly drain your funding, limit runway, and reduce your chances of reaching the next stage. In our case, we saw the industry shifting towards platforms like Snowflake as the preferred source of truth for teams’ day-to-day operations. This made our connected planning vision both costly to pursue and difficult to pivot.
If you are an early stage founder, know that the drunken walk of the early stage is unavoidable, but there is a method to the madness. I’ve shared my thoughts on how early stage teams can potentially increase their chances for a successful outcome here. While it’s valuable to learn from the strategies that helped other startups succeed, it’s just as important to study their mistakes. By understanding what went wrong, you can identify potential pitfalls and increase your own chances of success. As Charlie Munger puts it - “All I want to know is where I’m going to die, so I’ll never go there!”
Appendix